Большие данные в простом изложении: объяснение на простом английском языке
Цена по запросу
Июль 4, 2023
14
Большие данные стали громким словом в технологической отрасли, но что они означают на самом деле? Говоря простым языком, большие данные - это огромные объемы информации, генерируемые и собираемые компаниями, организациями и частными лицами. Эта информация может поступать из различных источников, включая социальные сети, онлайн-транзакции и датчики. Большие данные характеризуются своим объемом, скоростью и разнообразием и предоставляют ценные идеи и возможности для тех, кто знает, как анализировать и использовать большие данные.
Сам размер наборов больших данных может быть пугающим. По оценкам, каждый день мы создаем 2,5 кБайт данных. Это 2,5 и 18 нулей. Эти данные поступают из самых разных источников, включая текстовые сообщения, электронную почту, фотографии, видео и другие цифровые файлы. Объем данных ошеломляет, но что действительно отличает Большие данные, так это скорость, с которой они генерируются. В современном быстро меняющемся мире данные создаются с беспрецедентной скоростью, и компаниям и организациям необходимо уметь анализировать эти данные и действовать на их основе в режиме реального времени, чтобы оставаться конкурентоспособными.
Большие данные также характеризуются своим разнообразием. Они включают структурированные данные, такие как данные в электронных таблицах, которые упорядочены и легко поддаются поиску, и неструктурированные данные, такие как электронные письма, сообщения в социальных сетях и другая текстовая информация. Неструктурированные данные сложнее анализировать, но они также позволяют получить ценные сведения о поведении потребителей, анализе настроений и других областях, представляющих интерес.
В конечном счете, большие данные - это не просто размер массива данных, а понимание и возможности, которые можно получить, анализируя и используя эти данные. Используя передовые методы анализа, компании и организации могут обнаружить в данных закономерности, тенденции и корреляции, которые ранее были скрыты. Это позволяет им принимать более обоснованные решения, совершенствовать процессы и операции и внедрять инновации такими способами, которые ранее были невозможны.
Обзор больших данных
Большие данные - это очень большие и сложные массивы данных, которые невозможно эффективно обрабатывать и анализировать с помощью традиционных средств обработки данных. Такие наборы данных обычно имеют большой объем, разнообразие и скорость и могут поступать из различных источников, таких как социальные сети, датчики и машины.
Одной из характеристик Больших данных является их огромный размер. Наборы больших данных могут составлять от терабайтов до петабайтов и даже экзабайтов. Такой большой объем данных создает проблемы с точки зрения хранения, обработки и анализа.
Разнообразие данных - еще один важный аспект Больших Данных. К ним относятся структурированные данные (такие как числа и текст), полуструктурированные данные (такие как XML и JSON) и неструктурированные данные (такие как изображения, видео и сообщения в социальных сетях). Управление и понимание такого разнообразия данных требует специальных инструментов и методов.
Большие данные также характеризуются скоростью, то есть скоростью, с которой данные генерируются и обрабатываются. С ростом использования подключенных к Интернету устройств и обработки данных в режиме реального времени большие данные все чаще генерируются и анализируются практически в реальном времени.
Для осмысления больших данных и извлечения ценной информации организации используют различные методы, такие как интеллектуальный анализ данных, машинное обучение и предиктивная аналитика. Эти методы включают анализ данных для выявления закономерностей, тенденций и корреляций, которые могут помочь в принятии решений и стимулировать инновации.
В целом, большие данные способны произвести революцию в промышленности и предоставить ценные сведения предприятиям, правительствам и организациям. Однако анализ больших данных может также создавать проблемы с точки зрения конфиденциальности, безопасности и этики, поскольку они могут содержать личную и конфиденциальную информацию.
Что такое большие данные? Почему это важно?
Под большими данными понимаются большие, сложные наборы данных, которыми невозможно легко управлять, обрабатывать или анализировать с помощью традиционных методов обработки данных. Они характеризуются тремя ключевыми факторами: объемом, скоростью и разнообразием.
Объем: большие данные относятся к большим объемам данных, которые ежедневно генерируются из различных источников, таких как социальные сети, датчики и онлайн-транзакции. Эти данные могут составлять от терабайтов до петабайтов и более, что делает их хранение и обработку чрезвычайно сложной задачей.
Скорость: большие данные также характеризуются скоростью, которая относится к скорости, с которой данные генерируются и должны быть проанализированы. Традиционные методы обработки данных могут оказаться не в состоянии справиться с природой Больших данных в режиме реального времени, что требует новых технологий и подходов.
Разнообразие: большие данные могут принимать различные формы, включая структурированные, неструктурированные и полуструктурированные данные. Структурированные данные организованы и легко обрабатываются, например, данные, хранящиеся в базах данных. Неструктурированные данные, с другой стороны, включают текстовые данные, изображения, видео и сообщения в социальных сетях, которые сложнее анализировать.
Большие данные важны, поскольку они дают компаниям и организациям ценные сведения и возможности. С помощью передовой аналитики и технологий машинного обучения большие данные можно использовать для улучшения процесса принятия решений, оптимизации операций и выявления тенденций и закономерностей, которые могут привести к инновациям и конкурентным преимуществам.
Кроме того, большие данные позволяют разрабатывать персонализированный опыт и целевые маркетинговые стратегии. Анализируя данные о клиентах, организации могут понять их предпочтения и поведение и предложить им целевые продукты и услуги.
В целом, большие данные обладают потенциалом для преобразования отраслей промышленности и революции в том, как мы живем и работаем. Они позволяют организациям извлекать значимую информацию из огромных объемов данных и принимать решения, основанные на данных, которые могут стимулировать рост, эффективность и инновации.
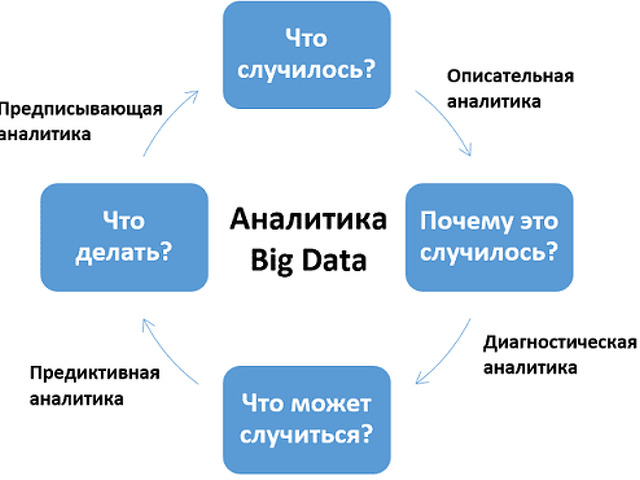
Три "V" Больших Данных
Когда речь идет о Больших данных, есть три ключевых элемента, которые определяют их природу и сложность. Их принято называть "3 V" Больших Данных: объем, скорость и разнообразие. Понимание этих аспектов важно для организаций, чтобы эффективно управлять и анализировать большие объемы данных.
Объем: объем относится к огромному количеству генерируемых и собираемых данных. С развитием технологий и ростом зависимости от цифровых платформ объем генерируемых данных растет экспоненциально. Сюда входят данные из различных источников, таких как социальные сети, датчики и транзакции. Обработка таких больших объемов данных требует надежной инфраструктуры и инструментов для хранения, обработки и анализа данных.
Скорость: скорость относится к скорости, с которой генерируются и обрабатываются данные. В современном быстро меняющемся мире данные генерируются с беспрецедентной скоростью. Будь то онлайн-транзакции, сообщения в социальных сетях или данные датчиков - скорость генерирования данных может быть просто ошеломляющей. Организациям необходимо иметь возможность собирать и обрабатывать эти данные в режиме реального времени или почти в режиме реального времени, чтобы извлекать ценные сведения и принимать обоснованные решения.
Разнообразие: разнообразие относится к различным типам и форматам собранных данных. Большие данные включают структурированные данные, такие как базы данных и электронные таблицы, а также неструктурированные и полуструктурированные данные. К ним относятся текст, изображения, аудио, видео и сообщения в социальных сетях. Управление и анализ таких разнообразных и сложных данных требует сложных алгоритмов и инструментов для извлечения значимой информации.
Помимо трех "V", при работе с большими данными необходимо учитывать и другие факторы, такие как правдивость (обеспечение точности и надежности данных) и ценность (потенциальные возможности и понимание сути данных). Понимая эти аспекты, организации могут эффективно использовать возможности больших данных и получить конкурентное преимущество в современном мире, основанном на данных.
Применение больших данных
Большие данные произвели революцию в различных отраслях промышленности и оказывают влияние на многие сферы нашей жизни. Вот некоторые примеры использования больших данных.
1. здравоохранение: аналитика больших данных используется в здравоохранении для улучшения результатов лечения пациентов, снижения затрат и выявления тенденций и закономерностей развития заболеваний. Например, медицинские учреждения могут анализировать большие объемы данных о пациентах для создания индивидуальных планов лечения и прогнозирования развития болезни.
2. розничная торговля: большие данные меняют индустрию розничной торговли, позволяя получить представление о поведении покупателей. Розничные компании могут анализировать историю покупок клиентов, данные социальных сетей и другие источники информации для создания персонализированных рекомендаций, улучшения управления запасами и оптимизации ценовых стратегий.
3. финансовая сфера: финансовые учреждения используют большие данные для выявления мошенничества, оценки кредитного риска и принятия обоснованных инвестиционных решений. Анализируя большие объемы финансовых данных, эти учреждения могут выявлять подозрительные операции, прогнозировать рыночные тенденции и создавать более точные модели рисков.
4. производство: большие данные используются в производстве для оптимизации производственных процессов, улучшения контроля качества и предотвращения поломок оборудования. Анализируя данные с датчиков и машин, производители могут выявлять узкие места, оптимизировать рабочие процессы и минимизировать время простоя.
5. транспорт: транспортные компании используют большие данные для оптимизации маршрутов, снижения расхода топлива и повышения безопасности. Анализируя данные с GPS-устройств, датчиков движения и записей технического обслуживания транспортных средств, эти компании могут принимать решения в режиме реального времени, чтобы оптимизировать свою деятельность и лучше обслуживать своих клиентов.
6. энергетика: Большие данные помогают энергетическому сектору повысить эффективность, снизить затраты и использовать возобновляемые ресурсы. Энергетические компании могут анализировать данные с интеллектуальных счетчиков, погодных датчиков и электросетей для оптимизации распределения энергии, прогнозирования спроса и выявления возможностей для экономии энергии.
Это лишь несколько примеров того, как большие данные применяются в различных отраслях. По мере развития технологий и получения все большего количества данных потенциал применения больших данных продолжает расширяться.
Большие данные в бизнесе
В современном цифровом мире большие данные становятся все более ценным активом для бизнеса. Собирая и анализируя большие объемы данных, компании могут получать глубокие знания и принимать обоснованные решения для улучшения деятельности и стимулирования роста.
Когда компании используют большие данные, они получают более глубокое понимание своих клиентов и их поведения, что позволяет им персонализировать свои маркетинговые стратегии и оптимизировать работу с клиентами. Анализируя данные о клиентах, компании могут выявлять закономерности и тенденции, сегментировать целевых пользователей и адаптировать услуги к потребностям и предпочтениям клиентов.
Кроме того, большие данные могут помочь компаниям повысить эффективность своей работы. Анализируя большие массивы данных, компании могут выявлять неэффективные процессы, цепочки поставок и операции, что позволяет им принимать решения, основанные на данных, для оптимизации работы и снижения затрат. Это позволяет им повысить производительность, оптимизировать операции и улучшить распределение ресурсов.
Кроме того, большие данные играют важную роль в управлении рисками предприятия и прогнозной аналитике. Анализируя исторические данные и выявляя закономерности и аномалии, компании могут прогнозировать потенциальные риски и принимать упреждающие меры по их снижению. Это позволяет компаниям делать более точные прогнозы, эффективно управлять рисками и принимать обоснованные решения для достижения успеха.
В заключение следует отметить, что большие данные произвели революцию в работе предприятий. Используя мощь аналитики данных, компании могут получить ценные сведения, улучшить процессы принятия решений и стимулировать рост и прибыльность в сегодняшней конкурентной бизнес-среде.
Большие данные в науке и исследованиях
В науке и исследованиях большие данные играют ключевую роль в развитии знаний и стимулировании инноваций. По мере увеличения объема, разнообразия и скорости генерируемых данных исследователи получают возможность анализировать и извлекать ценные сведения, которые ранее были недоступны.
Применение больших данных в науке и исследованиях позволяет ученым решать сложные проблемы, делать прогнозы и выявлять закономерности. Используя современные аналитические инструменты и методы, можно обрабатывать большие массивы данных, чтобы выявить взаимосвязи, которые могут привести к прорывным открытиям.
Одной из областей, где большие данные оказывают значительное влияние, является геномика. При изучении генетической информации генерируется огромное количество данных, анализ которых важен для понимания болезней, разработки персонализированной медицины и развития генетических исследований. Анализ больших данных позволяет ученым сравнивать и анализировать генетические последовательности в больших масштабах и выявлять закономерности и мутации, способствующие развитию заболеваний.
Еще одна область, где большие данные революционизируют исследования, - астрономия. Телескопы ежедневно получают огромное количество астрономических данных, позволяющих понять происхождение Вселенной, поведение небесных объектов и обнаружить экзопланеты. Технологии больших данных используются для обработки и анализа этих астрономических данных, позволяя ученым делать важные открытия и глубже понимать Вселенную.
Большие данные также играют определенную роль в экологических исследованиях. Собирая и анализируя данные из различных источников, таких как метеостанции, спутники и датчики, исследователи могут получить представление об изменении климата, биоразнообразии и влиянии деятельности человека на окружающую среду. Аналитика больших данных может помочь выявить тенденции, закономерности и аномалии в экологических данных, обеспечивая основу для принятия обоснованных решений и устойчивой практики.
В заключение следует отметить, что большие данные обладают огромным потенциалом в науке и исследованиях. Они позволяют исследователям изучать огромные объемы данных, выявлять скрытые закономерности и делать инновационные открытия. Используя возможности аналитики больших данных, ученые могут расширить границы знаний и стимулировать прогресс в различных научных дисциплинах.
Проблемы больших данных
Большие данные, характеризующиеся огромным объемом, скоростью и разнообразием, ставят ряд проблем перед организациями, стремящимися использовать их потенциал. Одной из основных проблем является хранение и управление большими массивами данных. Традиционные системы баз данных не приспособлены для работы с такими большими объемами данных, поэтому организациям необходимо инвестировать в новые технологии и инфраструктуру, способные хранить и обрабатывать большие данные.
Еще одна проблема, связанная с большими данными, - это качество данных. Из-за огромного объема генерируемых данных существует риск того, что данные могут быть неполными или неточными, что может привести к ошибочному анализу и принятию решений. Чтобы обеспечить качество данных, необходимо внедрить надежные процессы проверки и очистки данных для выявления и устранения несоответствий и ошибок.
Еще одной серьезной проблемой является скорость обработки больших данных. Скорость, с которой генерируются и обрабатываются данные, может перегрузить традиционные системы. Для своевременного извлечения информации и принятия обоснованных решений требуется обработка и анализ в режиме реального времени.
Разнообразие источников данных еще больше усложняет инициативы в области больших данных. Организациям необходимо интегрировать и анализировать данные из различных источников, включая структурированные и неструктурированные данные из социальных сетей, датчиков и журналов. Это требует специализированных инструментов и технологий для обработки различных форматов и структур данных.
Кроме того, большие данные создают проблемы конфиденциальности и безопасности. По мере увеличения объемов сбора и хранения данных организациям необходимо обеспечить защиту конфиденциальной информации. Нарушение конфиденциальности данных и несанкционированный доступ к ним могут иметь серьезные последствия, включая финансовые потери и ущерб репутации организации.
Наконец, большие данные также создают проблемы с точки зрения анализа и интерпретации данных. Извлечение значимых выводов из огромных объемов данных требует применения передовых аналитических методов и алгоритмов. Организациям требуются высококвалифицированные специалисты по данным, которые могут правильно понимать и интерпретировать данные, чтобы генерировать действенные идеи и ценность.
Конфиденциальность и безопасность данных.
Конфиденциальность и безопасность данных являются ключевыми проблемами в эпоху больших данных. По мере увеличения объема и доступности данных важно защитить личные данные от несанкционированного доступа и неправомерного использования.
Организациям, собирающим и анализирующим большие данные, необходимо уделять первостепенное внимание конфиденциальности данных, применяя надежные меры безопасности. Это включает в себя шифрование конфиденциальной информации, внедрение контроля доступа и регулярное обновление протоколов безопасности.
Кроме того, важную роль в защите прав на неприкосновенность частной жизни играют правила защиты данных, такие как Европейское общее положение о защите данных (GDPR). Эти нормы требуют, чтобы организации получали явное согласие на сбор и обработку данных, обеспечивали прозрачность для людей в отношении того, как используются их данные, и обеспечивали безопасное хранение и передачу персональных данных.
Для повышения безопасности данных организации могут использовать такие передовые методы, как анонимизация и токенизация. Анонимизация предполагает удаление из набора данных информации, позволяющей установить личность, а токенизация заменяет конфиденциальные данные уникальным идентификационным маркером. Эти методы минимизируют риск несанкционированного доступа или утечки данных.
Кроме того, обеспечение конфиденциальности и безопасности данных должно быть постоянным процессом, а не разовым мероприятием. Регулярные оценки рисков, аудиты и мониторинг необходимы для выявления и устранения потенциальных уязвимостей. Организациям также следует внедрять программы обучения сотрудников, чтобы повысить осведомленность о передовых методах защиты конфиденциальности данных и обеспечить соблюдение политик безопасности.
В заключение следует отметить, что защита конфиденциальности данных и обеспечение их безопасности является важным аспектом обработки больших данных. Внедряя надежные меры безопасности и соблюдая правила конфиденциальности данных, организации могут завоевать доверие общественности и свести к минимуму риски, связанные с утечкой и неправомерным использованием данных.
Качество и точность данных
Качество данных является важным аспектом при работе с большими данными. Для того чтобы данные были ценными и полезными, они должны быть точными и надежными. Низкое качество данных может привести к серьезным проблемам и подорвать весь процесс анализа данных и принятия решений.
Одной из основных проблем в обеспечении качества данных является отсутствие стандартизированных форматов и структур данных. Различные источники и системы имеют разные форматы данных, что затрудняет эффективную интеграцию и анализ данных. Это может привести к несоответствиям и ошибкам в данных, что может повлиять на точность данных.
Чтобы обеспечить качество и точность данных, организациям необходимо внедрить надежные методы управления данными. Это включает в себя установление стандартов качества данных, проведение регулярных аудитов данных и внедрение процессов очистки данных для выявления и устранения ошибок и несоответствий. Поддерживая чистоту и точность данных, организации могут принимать более обоснованные решения и извлекать из них значимую информацию.
Еще одним важным аспектом качества данных является их валидация. Она включает в себя проверку точности и полноты данных путем сравнения их с заранее определенными правилами или критериями. Методы проверки данных помогают обнаружить и предотвратить такие ошибки, как недостающие или неверные данные, и обеспечить высокое качество данных.
В дополнение к проверке данных для оценки общего качества данных можно использовать методы профилирования данных. Это предполагает анализ данных для выявления закономерностей, аномалий и несоответствий. Выявляя и решая проблемы, организации могут повысить качество и точность своих данных.
В заключение следует отметить, что качество и точность данных необходимы для принятия обоснованных решений и получения значимых выводов из больших данных. Практикуя управление данными, проводя регулярный аудит данных и используя методы проверки и профилирования данных, организации могут обеспечить точность, надежность и ценность своих данных.
Технология больших данных
Большие данные относятся к большим наборам структурированных, полуструктурированных и неструктурированных данных, которые требуют методов обработки и анализа, выходящих за рамки традиционных систем управления данными. Чтобы справиться с большими данными, были разработаны различные технологии для сбора, хранения, обработки и анализа больших объемов данных.
Одной из ключевых технологий, используемых в работе с большими данными, являются распределенные файловые системы. Эти файловые системы предназначены для хранения и управления данными на нескольких серверах, что позволяет эффективно хранить и извлекать большие объемы данных. Примерами распределенных файловых систем являются распределенная файловая система Hadoop (HDFS) и файловая система Google (GFS).
Другой важной технологией в области больших данных является Apache Hadoop, фреймворк с открытым исходным кодом, который позволяет распределенно обрабатывать большие массивы данных на кластерах компьютеров. Hadoop включает в себя различные компоненты, такие как Hadoop Distributed File System (HDFS), которая обеспечивает надежный и масштабируемый уровень хранения данных, и MapReduce, который позволяет параллельно обрабатывать данные.
Помимо Hadoop, все более популярными становятся такие платформы для обработки больших данных, как Apache Spark и Apache Flink. Эти платформы используют вычисления в памяти и оптимизированные алгоритмы для более быстрой и эффективной обработки больших данных.
Платформы для анализа больших данных также играют важную роль в обработке и анализе больших данных. Эти платформы предоставляют инструменты и технологии для выполнения таких задач, как ввод данных, преобразование данных, запрос данных и визуализация данных. Популярные платформы для анализа больших данных включают Apache Hadoop, Apache Spark и Apache Kafka.
Кроме того, чтобы справиться с масштабами и сложностью больших данных, компании часто используют базы данных NoSQL, которые предназначены для эффективной обработки неструктурированных и полуструктурированных данных Базы данных NoSQL обеспечивают гибкие модели данных и горизонтальную масштабируемость, что делает их подходящими для больших данных. Примерами баз данных NoSQL являются MongoDB, Cassandra и Apache HBase.
В заключение следует отметить, что технологии больших данных включают широкий спектр инструментов и методов для обработки и анализа больших объемов данных. Эти технологии позволяют организациям использовать ценность больших данных и получать информацию, которая может способствовать принятию более эффективных решений и инновациям.
Hadoop: платформа для работы с большими данными
Hadoop - это мощная и популярная платформа с открытым исходным кодом для обработки и хранения больших данных. Он позволяет организациям хранить и обрабатывать большие объемы данных в распределенной вычислительной среде. Hadoop предназначен для обработки различных типов данных и обеспечивает масштабируемое и отказоустойчивое решение для обработки больших данных.
В основе Hadoop лежит распределенная файловая система Hadoop (HDFS), которая разделяет данные и распределяет их между несколькими серверами в кластере Hadoop. HDFS использует архитектуру ведущий/ведомый, где один узел выступает в качестве ведущего узла, отвечающего за управление метаданными, а другие узлы выступают в качестве ведомых узлов для хранения и обработки данных. и обрабатывают данные.
Hadoop также включает модель программирования MapReduce, которую разработчики могут использовать для создания распределенных заданий обработки, которые могут обрабатывать большие наборы данных параллельно на кластерах. Одним из этапов является этап mapper, на котором данные разбиваются на пары ключ-значение и обрабатываются параллельно, а другим - этап reducer, на котором обработанные данные объединяются и агрегируются.
Помимо HDFS и MapReduce, экосистема Hadoop включает ряд инструментов и фреймворков, которые расширяют ее возможности. Некоторые из ключевых компонентов включают HBase, распределенную базу данных NoSQL. Hive - хранилище данных и SQL-подобный язык запросов; Pig - высокоуровневый язык сценариев обработки данных; и Spark - быстрый механизм обработки данных общего назначения. Эти компоненты позволяют выполнять на Hadoop различные виды обработки и анализа данных.
Hadoop стал стандартом де-факто для обработки и хранения больших данных благодаря своей распределенной и отказоустойчивой архитектуре. Он произвел революцию в том, как организации обрабатывают большие объемы данных, получая ценные сведения и позволяя принимать решения на основе данных. Поскольку объем больших данных продолжает расти, Hadoop будет оставаться важным инструментом в средах больших данных.
Машинное обучение и искусственный интеллект в больших данных
Машинное обучение и искусственный интеллект (ИИ) играют важную роль в анализе и понимании больших данных. Поскольку объем, скорость и разнообразие данных продолжают расти, традиционные методы анализа данных становятся неадекватными. Алгоритмы машинного обучения позволяют компьютерам автоматически учиться на основе данных и принимать прогнозы и решения без явного программирования. В сочетании с искусственным интеллектом это позволяет создавать интеллектуальные системы, способные обрабатывать и анализировать большие объемы данных в режиме реального времени.
Одним из способов использования машинного обучения и ИИ в работе с большими данными является предиктивная аналитика. Анализируя исторические данные, алгоритмы могут выявлять закономерности и тенденции и предсказывать будущие результаты. Это полезно для компаний в различных отраслях, таких как финансы, здравоохранение и маркетинг, поскольку может помочь им принимать обоснованные решения, оптимизировать процессы и повысить общую производительность.
Еще одним применением машинного обучения и ИИ в больших данных является обработка естественного языка (NLP), которая позволяет компьютерам понимать и интерпретировать человеческий язык и извлекать ценную информацию из неструктурированных источников данных, таких как сообщения в социальных сетях, электронные письма и отзывы клиентов. из неструктурированных источников данных, таких как сообщения в социальных сетях, электронные письма и отзывы клиентов. Это позволяет компаниям получать глубокое понимание и анализ настроений, автоматизировать поддержку клиентов и повысить уровень персонализации.
Кроме того, машинное обучение и ИИ позволяют разрабатывать рекомендательные системы. Эти системы используют алгоритмы для анализа поведенческих данных клиентов и индивидуальной рекомендации продуктов и услуг. Используя большие объемы данных, эти системы предоставляют точные и актуальные рекомендации, улучшая общее восприятие клиента и повышая продажи.
В целом, машинное обучение и искусственный интеллект являются важнейшими компонентами аналитики больших данных. Они позволяют компаниям максимально использовать потенциал своих данных, делая точные прогнозы, извлекая ценные сведения из неструктурированных данных и предоставляя персонализированные рекомендации. По мере дальнейшего роста больших данных эти технологии будут приобретать все большее значение, меняя методы работы компаний и принятия решений на основе данных.
Аналитика больших данных
Аналитика больших данных - это процесс изучения больших, сложных массивов данных для выявления скрытых закономерностей, корреляций и выводов, которые могут быть использованы для принятия обоснованных бизнес-решений. Она предполагает использование передовых аналитических методов и инструментов для анализа огромных объемов данных из различных источников, включая социальные сети, датчики и транзакционные системы.
Одной из основных проблем в аналитике больших данных является обработка огромных объемов данных. Традиционные методы и инструменты обработки данных не подходят для обработки таких больших массивов данных. Поэтому для обработки и анализа больших данных используются специализированные технологии, такие как распределенные вычисления и параллельная обработка.
Анализ больших данных позволяет получить ценные сведения и помогает организациям улучшить работу, оптимизировать процессы и принимать решения на основе данных. Анализируя большие объемы данных, компании могут выявлять тенденции, обнаруживать аномалии и прогнозировать будущие результаты. Эта информация может быть использована для улучшения обслуживания клиентов, оптимизации маркетинговых кампаний, улучшения разработки продуктов и оптимизации операций.
В аналитике больших данных используется несколько методов и инструментов, включая интеллектуальный анализ данных, машинное обучение, обработку естественного языка и предиктивное моделирование. Эти методы позволяют организациям извлекать ценную информацию из неструктурированных и структурированных данных, выявлять закономерности и тенденции и делать точные прогнозы.
В заключение следует отметить, что аналитика больших данных - это мощный инструмент, который позволяет организациям получать ценные сведения из огромных объемов данных. Используя передовые методы и инструменты анализа, компании могут принимать обоснованные решения, оптимизировать процессы и повышать общую производительность.
Добыча данных и предиктивная аналитика
Добыча данных и предиктивная аналитика - два тесно связанных понятия, которые играют важную роль в мире больших данных. Добыча данных подразумевает извлечение ценной информации и закономерностей из больших массивов данных. Добыча данных позволяет организациям использовать различные алгоритмы и методики для выявления скрытых сведений, которые могут быть использованы для улучшения процесса принятия решений и повышения эффективности работы.
Предиктивная аналитика, с другой стороны, продвигает процесс добычи данных на шаг вперед, используя извлеченную информацию для прогнозирования будущих событий и результатов. Используя статистические модели и алгоритмы машинного обучения, предиктивная аналитика может помочь организациям предвидеть тенденции, предсказывать поведение клиентов и принимать обоснованные решения.
Одно из распространенных применений интеллектуального анализа данных и предиктивной аналитики - сегментация клиентов. Анализируя данные о клиентах, организации могут выявлять закономерности и объединять клиентов в различные сегменты на основе их предпочтений, поведения и демографических характеристик. Эта информация может быть использована для персонализации маркетинговых кампаний, повышения удовлетворенности клиентов и увеличения продаж.
Другим примером использования является выявление мошенничества. Анализируя большие объемы данных, организации могут обнаружить закономерности и аномалии, которые могут указывать на мошенничество. Такие выводы могут помочь предотвратить финансовые потери и защитить клиентов от мошеннических операций.
Анализ данных и предиктивная аналитика также применяются в здравоохранении, финансах, управлении цепочками поставок и многих других отраслях. С увеличением доступности больших данных и развитием технологий организации могут использовать эти мощные инструменты для получения конкурентных преимуществ и стимулирования инноваций.
Анализ в реальном времени и принятие решений
В мире больших данных аналитика в реальном времени и принятие решений играют ключевую роль, помогая компаниям оставаться конкурентоспособными и принимать обоснованные решения. Аналитика в реальном времени - это способность анализировать данные по мере их получения, что позволяет организациям извлекать ценные сведения и принимать незамедлительные меры.
По мере увеличения объема и скорости передачи данных аналитика в реальном времени становится необходимой для компаний, чтобы оставаться на шаг впереди. Это позволяет им отслеживать и анализировать данные в режиме реального времени, давая четкое представление о текущем состоянии бизнеса. Это позволяет организациям быстро реагировать на изменения рынка, поведение клиентов или внутренние операции.
Аналитика в реальном времени особенно важна в таких отраслях, как финансы, электронная коммерция и управление цепочками поставок, где даже небольшие задержки в принятии решений могут привести к значительным финансовым потерям. Используя аналитику в реальном времени, компании могут обнаруживать и реагировать на аномалии, выявлять закономерности и принимать своевременные решения на основе данных.
Аналитика в реальном времени возможна благодаря использованию передовых технологий, таких как платформы больших данных, инструменты потоковой аналитики и алгоритмы машинного обучения. Эти технологии позволяют организациям обрабатывать и анализировать огромные объемы данных в режиме реального времени, предоставляя действенные выводы со скоростью бизнеса.
В заключение следует отметить, что анализ в режиме реального времени и принятие решений являются ключевыми элементами успешной стратегии работы с большими данными. Используя информацию в реальном времени, компании могут получить конкурентное преимущество, повысить операционную эффективность и принимать обоснованные решения, способствующие росту и успеху.
Оставить комментарий
Похожие объявления
 Март 9, 2024
Март 9, 2024
Клининг-Тюмень, заказать клининг в Тюмени
Тюмень
50.00 ₽
 Сентябрь 18, 2023
Сентябрь 18, 2023
Генеральная Уборка
Симферополь
2500.00 ₽
 Июль 4, 2023
Июль 4, 2023
Бесплатная платформа для обмена ссылками
Волоколамск
Цена по запросу
 Июль 4, 2023
Июль 4, 2023
Биржа рекламы на Одноклассниках: новые возможности для охвата аудитории
Усть-Илимск
Цена по запросу
Комментарии