Анализ стоп-слов
Цена по запросу
Июль 4, 2023
7
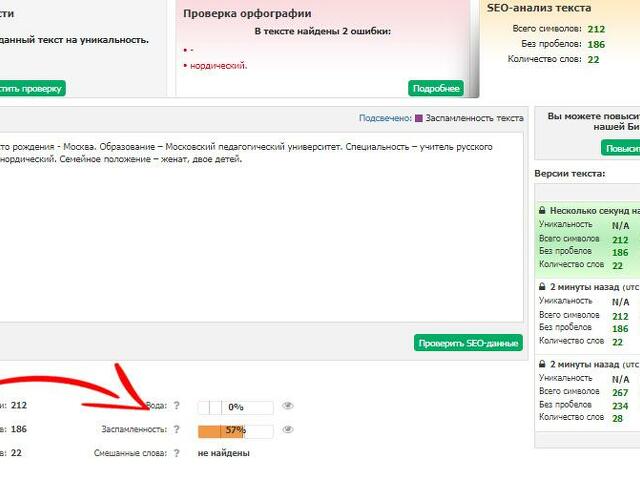
Стоп-слова - это общее понятие в обработке естественного языка. Они относятся к словам, которые считаются неважными или нерелевантными в определенном контексте. Такие слова часто отфильтровываются или игнорируются для повышения эффективности и точности алгоритмов анализа текста.
Стоп-слова могут варьироваться в зависимости от конкретной задачи или области. Обычные примеры стоп-слов включают артикли, предлоги и местоимения. Эти слова часто используются в повседневном языке, но сами по себе не являются значимыми.
При анализе данных естественного языка важно учитывать использование стоп-слов. Их удаление снижает уровень шума и позволяет сосредоточиться на более важном содержимом. Однако решение об удалении стоп-слов следует принимать осторожно, поскольку некоторые стоп-слова могут передавать информацию, значимую в определенном контексте.
Понимание стоп-слов и их влияния на текстовый анализ крайне важно для всех, кто работает с данными естественного языка. Выявляя и анализируя стоп-слова, исследователи и разработчики могут повысить точность и эффективность алгоритмов и получить более осмысленные и релевантные результаты.
Что такое стоп-слова? Почему стоп-слова важны для анализа текста?
Стоп-слова являются общим понятием в анализе текста и обычно относятся к словам, которые считаются неважными или нерелевантными для понимания смысла текста. Это часто функциональные слова или часто встречающиеся слова, которые не имеют большого семантического значения. Примеры распространенных стоп-слов включают "и", "the", "in" и "a".
Стоп-слова важны для анализа текста, поскольку они могут оказывать значительное влияние на результаты задач обработки естественного языка, таких как анализ настроений, моделирование тем и поиск информации. Удаление стоп-слов из текста позволяет исследователям и специалистам по работе с данными сосредоточиться на более значимых словах, которые передают важную информацию и позволяют понять основные закономерности и темы.
Удаление стоп-слов из текста полезно по нескольким причинам. Во-первых, это уменьшает размерность данных, что облегчает их обработку и анализ. Удаление слов, которые не вносят значительного вклада в общее понимание, делает анализ более целенаправленным и точным. Во-вторых, удаление стоп-слов снижает вычислительные затраты и повышает эффективность алгоритмов и моделей, используемых при анализе текста.
Однако важно отметить, что список стоп-слов, используемых при анализе текста, может меняться в зависимости от конкретной задачи или анализируемого языка. Некоторые слова обычно считаются стоп-словами, но в определенных контекстах эти слова могут быть значимыми. Поэтому важно тщательно оценить влияние удаления стоп-слов и учитывать конкретные требования анализа.
В заключение следует отметить, что стоп-слова играют важную роль в анализе текста, позволяя исследователям и специалистам по обработке данных сосредоточиться на значимых словах и извлечь ценную информацию. Удаление стоп-слов повышает точность и эффективность анализа, но при принятии решения о том, какие слова исключить, важно учитывать контекст и цель анализа.
Зачем анализировать стоп-слова в NLP и SEO?
Стоп-слова - это часто используемые слова, которые обычно исключаются или игнорируются в задачах обработки естественного языка (NLP) и оптимизации поисковых систем (SEO). Важно анализировать эти стоп-слова, поскольку они могут оказывать значительное влияние на качество и релевантность обрабатываемого текста или веб-страницы.
1. Улучшение модели НЛП: анализ стоп-слов может помочь улучшить точность и эффективность модели НЛП. Удаляя или заменяя нерелевантные стоп-слова, модель может сосредоточиться на более важных и значимых словах, что приводит к улучшению семантического понимания и обработки языка.
2. Улучшение рейтинга поисковых систем: в SEO стоп-слова могут влиять на рейтинг веб-страницы в поисковых системах. Анализ и оптимизация использования стоп-слов улучшает видимость и релевантность контента для поисковых систем. Это может улучшить ранжирование и увеличить органический трафик.
3. фильтрация шума в текстовых данных: стоп-слова часто включают общие слова с небольшим конкретным значением, такие как "is", "the" и "and". Анализ и удаление таких стоп-слов снижает уровень шума в текстовых данных и позволяет проводить более точный и эффективный анализ и извлекать значимую информацию.
4. уменьшение размера набора данных: анализ и удаление стоп-слов также может помочь уменьшить размер набора данных, используемых для анализа и обработки текста. Это особенно полезно, когда память или вычислительные ресурсы ограничены. Удаление ненужных стоп-слов делает набор данных более компактным и простым в управлении.
5. настройка списков стоп-слов: анализ стоп-слов позволяет вам настраивать списки стоп-слов на основе конкретных областей или требований. В различных отраслях или дисциплинах может быть свой собственный набор стоп-слов, более подходящих для конкретного контекста. Анализируя и адаптируя свой список стоп-слов, вы можете еще больше повысить точность и релевантность ваших задач NLP или SEO.
В целом, анализ стоп-слов важен для NLP и SEO по ряду причин, включая повышение производительности модели, оптимизацию рейтинга поисковых систем, фильтрацию шума, уменьшение размера набора данных и настройку списков стоп-слов. Понимание и эффективное управление стоп-словами позволяет добиться лучших результатов в задачах анализа и обработки текста.
Как определить и удалить стоп-слова в тексте
Одним из распространенных этапов предварительной обработки при анализе текстовых данных является выявление и удаление стоп-слов. Стоп-слова - это слова, часто используемые в языке, которые не несут большой смысловой нагрузки или информации. Примерами стоп-слов в английском языке являются "the", "is", "and", "in" и "it".
Существует несколько способов выявления и удаления стоп-слов в тексте. Один из распространенных способов - использовать заранее составленный список стоп-слов и сравнивать каждое слово в тексте с этим списком.
Ниже приведен пример использования языка Python для определения и удаления стоп-слов.
Сначала необходимо импортировать список стоп-слов из библиотеки обработки естественного языка, например NLTK.
Затем текст разбивается на отдельные слова или лексемы.
Затем каждая лексема сравнивается со списком стоп-слов. Если лексема попадает в список стоп-слов, она удаляется из текста.
Наконец, оставшиеся лексемы снова объединяются в обработанный текст без стоп-слов.
Удаление стоп-слов позволяет сосредоточиться на более значимых словах в тексте, что повышает точность и эффективность задач анализа текста, таких как анализ настроений и тематическое моделирование. Однако важно отметить, что при принятии решения о том, какие слова включать или исключать в качестве стоп-слов, необходимо учитывать контекст и конкретные требования анализа.
В дополнение к предварительно определенным спискам стоп-слов, пользовательские списки стоп-слов также могут быть созданы на основе конкретных доменов или приложений. Благодаря включению стоп-слов, специфичных для конкретной области, этапы предварительной обработки могут быть дополнительно адаптированы к конкретным потребностям.
В заключение следует отметить, что выявление и удаление стоп-слов в тексте является важным этапом предварительной обработки при анализе текста. Удаление этих обычных слов позволяет сосредоточиться на более значимом и полезном содержимом текста, что приводит к более точным и эффективным результатам анализа.
Влияние стоп-слов на классификацию текста и анализ настроений
Стоп-слова - это часто используемые слова, которые, как считается, вносят незначительный или нулевой вклад в общий смысл текста. Примерами стоп-слов являются "the", "is", "and" и "a". При обработке естественного языка стоп-слова часто удаляются из текстовых данных в качестве предварительного этапа обработки, исходя из того, что они не дают полезной информации для таких задач, как классификация текста или анализ настроения.
Стоп-слова могут оказывать значительное влияние на классификацию текста и анализ настроения. С другой стороны, удаление стоп-слов уменьшает размерность данных и повышает эффективность алгоритмов машинного обучения. Отказ от часто используемых слов смещает фокус на более информативные термины с дискриминационной способностью.
С другой стороны, удаление стоп-слов может привести к потере важной информации. Некоторые стоп-слова могут нести контекстуальную информацию или передавать определенные эмоции. Например, в анализе настроений стоп-слова, такие как "не" и "но", могут оказывать значительное влияние на полярность предложения. Удаление этих слов может исказить результаты анализа настроений.
Для уменьшения влияния стоп-слов на классификацию текста и анализ настроений можно использовать различные подходы; один из них заключается в использовании списков стоп-слов, специфичных для конкретной области. Настройка списка стоп-слов для конкретной области или задачи позволяет сохранить релевантные стоп-слова и исключить нерелевантные.
Другой подход заключается в рассмотрении контекста, в котором встречается стоп-слово. Вместо того чтобы слепо удалять все случаи употребления стоп-слова, его важность может быть определена на основе соседних слов и фраз. Это позволяет проводить более тонкий и зависящий от контекста анализ стоп-слов.
В заключение следует отметить, что стоп-слова оказывают заметное влияние на классификацию текстов и анализ настроений. Удаление стоп-слов повышает эффективность, но при этом важно тщательно учитывать конкретную задачу и контекст, в котором будет проводиться анализ. Важно найти баланс между удалением нерелевантных стоп-слов и сохранением важных для получения точных и значимых результатов в задачах анализа текста.
Преимущества настройки списков стоп-слов для различных приложений
Стоп-слова - это обычные слова, часто используемые в английском языке, но малозначимые. Они часто игнорируются в задачах анализа текста, таких как поиск информации, моделирование тем и анализ настроения. Однако список стоп-слов по умолчанию подходит не для всех приложений. Настройка списка стоп-слов дает несколько преимуществ с точки зрения повышения точности и релевантности результатов.
1. релевантность для конкретной области: различные приложения имеют разные области и темы. Настройка списка стоп-слов может повысить релевантность анализа за счет удаления слов, характерных для конкретной области. Например, при анализе медицинских текстов в список стоп-слов можно добавить такие специфические для данной области слова, как "пациент", "болезнь" и "лечение", чтобы сосредоточиться на более значимых терминах.
2. Соображения, связанные с конкретным языком: стоп-слова не одинаковы во всех языках. Некоторые слова могут считаться стоп-словами в одном языке, но иметь важное значение в другом. Настройка списка стоп-слов в зависимости от языка текста может повысить точность и интерпретируемость анализа.
3. понимание контекста: списки стоп-слов часто содержат такие распространенные слова, как "the", "a" и "and". Однако, в зависимости от контекста, эти слова могут содержать важную информацию. Настраивая список стоп-слов в зависимости от конкретного контекста анализа, эти слова можно сохранить или удалить в зависимости от их значимости.
4. эффективность: настройка списка стоп-слов снижает потребность в вычислительных ресурсах и повышает эффективность анализа. Удаление нерелевантных слов на этапе предварительной обработки экономит время и вычислительные ресурсы, поскольку анализ может быть сосредоточен на более релевантных терминах.
5. гибкость: настройка списка стоп-слов позволяет гибко адаптировать анализ к специфическим требованиям каждого приложения. У разных приложений могут быть разные цели, и настройка списка стоп-слов позволяет соответствующим образом адаптировать анализ.
В заключение следует отметить, что создание индивидуальных списков стоп-слов для различных приложений дает множество преимуществ, включая релевантность для конкретной области, учет специфики языка, понимание контекста, повышение эффективности и гибкость. Создание индивидуального списка стоп-слов может значительно повысить точность и релевантность анализа текста, обеспечивая более значимые выводы и результаты.
Оставить комментарий
Похожие объявления
 Март 9, 2024
Март 9, 2024
Клининг-Тюмень, заказать клининг в Тюмени
Тюмень
50.00 ₽
 Сентябрь 18, 2023
Сентябрь 18, 2023
Генеральная Уборка
Симферополь
2500.00 ₽
 Июль 4, 2023
Июль 4, 2023
Бесплатная платформа для обмена ссылками
Волоколамск
Цена по запросу
 Июль 4, 2023
Июль 4, 2023
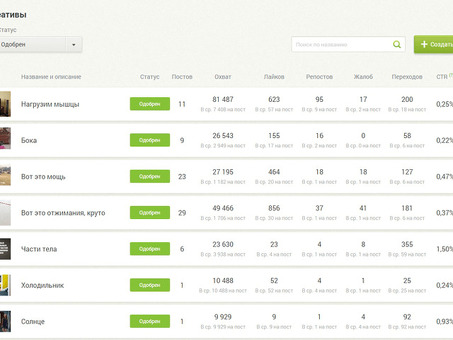
Биржа рекламы на Одноклассниках: новые возможности для охвата аудитории
Усть-Илимск
Цена по запросу
Комментарии