Алгоритмы бесконтрольного обучения: исчерпывающее руководство
Цена по запросу
Июль 4, 2023
3
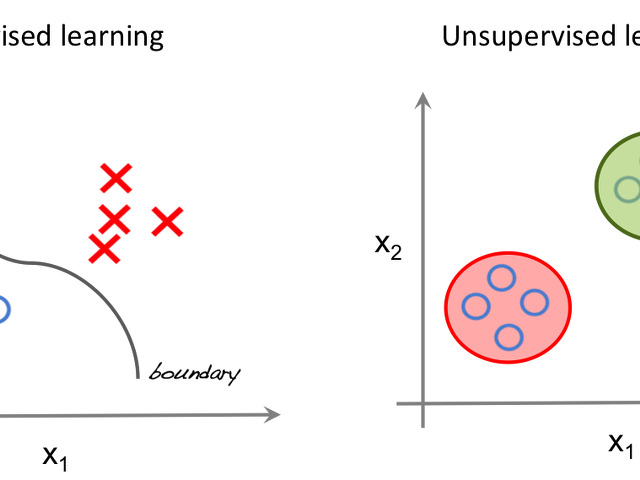
В области машинного обучения алгоритмы бесконтрольного обучения играют важную роль в извлечении закономерностей и структур из немаркированных данных. В отличие от контролируемого обучения, которое опирается на маркированные данные для обучения моделей, алгоритмы неконтролируемого обучения предназначены для выявления взаимосвязей и понимания из необработанных, неструктурированных данных.
Одним из основных преимуществ обучения без надзора является то, что оно может обрабатывать большие объемы данных без необходимости ручной аннотации. Это особенно полезно в сценариях, когда меченых данных мало или их получение обходится дорого. Автоматически выявляя скрытые закономерности и зависимости, алгоритмы бессупервизорного обучения позволяют ученым и исследователям выявлять ценную информацию и принимать решения на основе данных.
Существуют различные типы алгоритмов неконтролируемого обучения, каждый из которых имеет свои сильные стороны и сферы применения. Например, алгоритмы кластеризации группируют похожие точки данных на основе их характеристик, позволяя выявлять отдельные кластеры. Алгоритмы уменьшения размерности, с другой стороны, направлены на уменьшение количества признаков в наборе данных при сохранении значимой информации о наборе данных. Алгоритмы поиска правил корреляции пытаются выявить связи и зависимости между переменными в наборе данных.
В этом подробном руководстве подробно описаны различные типы алгоритмов бесконтрольного обучения, лежащие в их основе принципы и применение в различных областях. В нем рассматриваются преимущества и ограничения каждого алгоритма, а также лучшие практики их применения для решения реальных задач. Независимо от того, новичок вы или опытный практик, это руководство даст вам знания и понимание, необходимые для использования возможностей алгоритмов бессупервизорного обучения.
Что такое бесконтрольное обучение?
Бесподчиненное обучение - это метод машинного обучения, при котором модели обучаются без использования маркированных данных или явных указаний человека-эксперта. Другими словами, его цель - найти закономерности или структуры в данных без предварительных знаний или заранее определенных результатов. В отличие от контролируемого обучения, где алгоритму для обучения предоставляются маркированные примеры, алгоритмы неконтролируемого обучения анализируют входные данные без ссылок на известные результаты.
При обучении без надзора алгоритм работает с набором данных, который не имеет соответствующих выходных значений и содержит только входные признаки. Цель состоит в том, чтобы обнаружить уникальные закономерности, взаимосвязи или группировки в данных. Выявляя эти скрытые структуры, алгоритмы неконтролируемого обучения могут раскрыть ценные идеи и извлечь полезную информацию.
Кластеризация - популярный метод обучения без надзора, цель которого - сгруппировать похожие точки данных. Алгоритм анализирует входные данные и создает кластеры на основе сходства или несходства между точками данных. Это помогает понять базовую структуру набора данных и полезно для различных приложений, таких как сегментация потребителей, распознавание образов и обнаружение аномалий.
Другим подходом к обучению без надзора является снижение размерности. Его цель - уменьшить количество входных признаков, сохранив при этом большую часть важной информации. Уменьшение размерности данных облегчает визуализацию и анализ сложных наборов данных. Методы уменьшения размерности, такие как анализ главных компонент (PCA) и t-распределительное вероятностное встраивание окрестностей (t-SNE), широко используются в различных областях, таких как обработка изображений, обработка естественного языка и биоинформатика.
В целом, обучение без наблюдения играет важную роль в поиске закономерностей, выявлении выбросов и извлечении ценной информации из неструктурированных или немаркированных данных. Оно обеспечивает мощный подход для получения информации и составления прогнозов в различных областях, где маркированные данные ограничены или недоступны.
Типы алгоритмов бесконтрольного обучения
Алгоритмы бесконтрольного обучения можно разделить на различные типы в зависимости от их подхода и цели. Некоторые общие типы таковы.
1. Алгоритмы кластеризации: эти алгоритмы направлены на группировку похожих точек данных на основе их характеристик. Они выявляют закономерности или кластеры в данных без использования заранее определенных меток или классов. К распространенным алгоритмам кластеризации относятся кластеризация K-means, иерархическая кластеризация и DBSCAN.
2. алгоритмы снижения размерности: эти алгоритмы уменьшают количество переменных или признаков в наборе данных, сохраняя при этом важную информацию. Их цель - уловить основную структуру данных и устранить нерелевантные или избыточные признаки. Анализ главных компонент (PCA) и t-SNE (t Variance Probabilistic Neighbourhood Embedding) являются широко используемыми алгоритмами уменьшения размерности.
3. Обучение правилам ассоциаций: этот тип алгоритмов обнаруживает интересные связи или ассоциации между различными элементами в наборе данных. Они часто используются в анализе рыночной корзины для выявления часто встречающихся товаров; Apriori и FP-growth - распространенные алгоритмы обучения правилам корреляции.
4. алгоритмы обнаружения аномалий: эти алгоритмы определяют и выявляют редкие или необычные точки данных, которые значительно отклоняются от нормы. Они используются для выявления выбросов или аномалий в наборе данных, которые могут указывать на мошенничество, сбой системы или другое необычное поведение. Обычно используемые алгоритмы обнаружения аномалий включают Isolation Forest, Local Outlier Factor (LOF) и One-Class SVM.
5. генеративные модели: генеративные модели могут изучать базовое распределение вероятностей входных данных и генерировать новые образцы, которые похожи на исходное распределение данных. Эти модели могут использоваться для решения различных задач, таких как генерация новых изображений, текста или аудио. Популярные генеративные модели включают вариативные автоэнкодеры (VAEs) и генеративные сети состязательного типа (GANs).
Каждый тип алгоритмов обучения без наблюдения имеет свои сильные и слабые стороны, и выбор зависит от характера конкретной задачи и данных. Использование комбинации этих алгоритмов часто дает более полное представление о данных и способствует принятию более эффективных решений.
Области применения несамостоятельного обучения
Алгоритмы обучения без наблюдения имеют широкий спектр применения в самых разных областях. Одно из наиболее распространенных применений - кластеризация. Кластеризация использует алгоритмы для группировки похожих точек данных на основе атрибутов. Это может использоваться для сегментации клиентов, группировки клиентов со схожими предпочтениями и поведением для проведения целевых маркетинговых кампаний и персонализированных рекомендаций.
Еще одно применение обучения без контроля - обнаружение аномалий. Анализируя закономерности в наборе данных, алгоритмы самоконтролируемого обучения могут выявлять аномальные или отклоняющиеся точки данных, которые не соответствуют ожидаемой схеме. Это может быть использовано для выявления мошенничества и отметки необычных финансовых операций для дальнейшего расследования.
Алгоритмы неконтролируемого обучения также могут использоваться для снижения размерности. При работе с высокоразмерными наборами данных эти алгоритмы могут выявить наиболее важные характеристики или измерения, которые отражают наибольшие различия в данных. Это полезно для визуализации данных, когда высокоразмерные данные могут быть спроецированы в низкоразмерное пространство для облегчения интерпретации.
Еще одно применение - рекомендательные системы. Алгоритмы обучения без надзора могут анализировать поведение и предпочтения пользователей для выявления сходства между ними и рекомендовать продукты или контент на основе этого сходства. Это может быть использовано платформами электронной коммерции и сервисами потоковой передачи контента для предоставления пользователям персонализированных рекомендаций.
Наконец, алгоритмы обучения без надзора могут также использоваться для распознавания образов. Обучаясь на больших массивах данных, эти алгоритмы учатся определять общие закономерности и структуры в данных и могут использоваться для таких задач, как распознавание изображений и речи. Они могут использоваться в различных областях, включая здравоохранение, безопасность и финансы.
Оценка и сравнение алгоритмов бессупервизорного обучения
При оценке и сравнении алгоритмов обучения без надзора необходимо учитывать несколько важных факторов. Эти факторы включают точность алгоритма, вычислительную эффективность и способность обрабатывать различные типы данных.
Точность - один из самых важных критериев оценки алгоритмов обучения без надзора. Она означает, насколько точно алгоритм может выявить закономерности и взаимосвязи в данных без необходимости использования маркированных примеров. Обычно он измеряется с помощью такой метрики, как качество кластеризации, которая оценивает, насколько хорошо алгоритм может группировать похожие точки данных.
Вычислительная эффективность также является важным фактором при сравнении алгоритмов обучения без надзора. Это означает, насколько эффективно алгоритм может обрабатывать большие объемы данных за разумное время. Некоторые алгоритмы более эффективны, чем другие, и поэтому подходят для определенных приложений, где скорость является приоритетом.
Способность обрабатывать различные типы данных является еще одним важным фактором при оценке алгоритмов обучения без надзора. Некоторые алгоритмы могут быть разработаны специально для числовых данных, в то время как другие могут больше подходить для категориальных или текстовых данных. Для достижения точных и значимых результатов важно выбрать правильный алгоритм для конкретного типа анализируемых данных.
Кроме того, полезно сравнивать алгоритмы обучения без надзора, используя различные методы оценки. Это включает перекрестную валидацию, когда алгоритмы обучаются и тестируются на разных подмножествах данных, и сравнение производительности различных алгоритмов с использованием эталонных наборов данных. Учитывая эти факторы и применяя тщательные методы оценки, исследователи и практики могут определить, какой алгоритм обучения без надзора лучше всего подходит для их конкретных нужд.
Оставить комментарий
Похожие объявления
 Март 9, 2024
Март 9, 2024
Клининг-Тюмень, заказать клининг в Тюмени
Тюмень
50.00 ₽
 Сентябрь 18, 2023
Сентябрь 18, 2023
Генеральная Уборка
Симферополь
2500.00 ₽
 Июль 4, 2023
Июль 4, 2023
Бесплатная платформа для обмена ссылками
Волоколамск
Цена по запросу
 Июль 4, 2023
Июль 4, 2023
Биржа рекламы на Одноклассниках: новые возможности для охвата аудитории
Усть-Илимск
Цена по запросу
Комментарии